Let’s unleash the power of Go and Colly to see how we can scrape Amazon’s product list.

Introduction
This post is the follow up to my previous article. If you haven’t already done it, I’d recommend that you have a look at it so you can have a better understanding of what I’m talking about here and it will be easier for you to code along.
In this writing, I’ll show you how to improve the project we started by adding functionalities such as random User-Agent, proxies switcher, pagination handling, random delays between requests, and parallel scraping.
The goal of those methods is first, to improve the harvesting’s speed of the information we need. Second, we also need to avoid getting blocked by the platform we’re extracting data from. Some websites will block you if they notice you’re sending too many requests to them. I want to specify that our goal here is not to flood them with requests, but just to avoid getting blocked while extracting the data we need at an appropriate speed.
The Implementation
Randomize the User-Agent
The “User-Agent” is like the identifier of your browser and operating system. This information is usually sent with every request you make to a website. To know what’s your current User-Agent, you can write “What’s my user agent” in Google and you’ll find out the answer.
Why do we need to randomize it?
The User-Agent needs to be randomized to avoid your script getting detected by the source we’re getting data from (Amazon in our case). For instance, if the people working at Amazon notice that a lot of requests contain the same User-Agent string, they could block you thanks to this information.
The solution
Lucky for us, Colly provides a package called extensions. As you can see in the documentation, it contains a method called RandomUserAgent . It simply takes our Collector as a parameter.
| extensions.RandomUserAgent(c) |
And that’s it! With this line of code, Colly will now generate a new User-Agent string before every request.
You can also specify the following code in the OnRequest method:
| fmt.Println("UserAgent", r.Headers.Get("User-Agent")) |
That way, our program will print the User-Agent string it uses before sending the requests and we can make sure the method provided by the extensions package works
Pagination
For now, we’re only scraping the first result’s page of Amazon. It would be great to get a more complete set, right?
If we take a look at the result’s page. We notice that the pagination can be changed via the URL:
https://www.amazon.com/s?k=nintendo+switch&page=1We also observe that Amazon doesn’t allow us to go over page 20:

With that information, we can determine that all the result page can be accessed by modifying the c.Visit(url) in our current code.
| for i := 1; i <= 20; i++ { | |
| fullURL := fmt.Sprintf("https://www.amazon.com/s?k=nintendo+switch&page=%d", i) | |
| c.Visit(fullURL) | |
| } |
Thanks to a for loop, we’re now sending requests to all the pages from 1 to 20. This allows us to get more products’ information.
Parallelism
If you try to start the script at this point, you’ll notice that it isn’t very fast. It takes around 30 seconds to fetch the 20 pages. Lucky us, Colly provides parallelism out of the box. You just have to specify an option in the NewCollector method when you create the Collector .
| func main() { | |
| c := colly.NewCollector( | |
| colly.Async(true), | |
| ) | |
| // ... | |
| c.Wait() | |
| } |
This option basically says to Colly: “You don’t have to wait that a request ends to start the next ones”. The c.Wait() at the end is here to make the program wait until all the concurrent requests are done.
If you run this piece of code now, you’ll see that it is much faster than our first try. The console output will be a bit messy due to the fact that multiple requests print data at the same time, but the whole process should take approximately 1 second to be done. We see here that it is quite an improvement compared to the 30 seconds of our first try!
Random delays between every request
In order to avoid getting blocked and also for your bot to appear more like a human, you can set random delays between every request. Colly provides a Limit method that allows you to specify some set of rules.
| c.Limit(&colly.LimitRule{ | |
| RandomDelay: 2 * time.Second, | |
| Parallelism: 4, | |
| }) |
Here you can notice that I added a random delay of 2 seconds. It means that between the requests, there will be a random delay of a maximum of 2 seconds that will be added.
As you can see, I also added a Parallelism rule. This determined the maximum number of request that will be executed at the same time.
If we run our program now, we can see that it runs a bit slower than previously. This is due to the rules we just set. We need to define a balance between the scraping speed we need and the chances of getting blocked by the target website.
Proxy Switcher
Why do we need a proxy switcher?
One of the main thing that can get us blocked while scraping a website is our IP address. In our case, if Amazon notices that a large number of requests is sent from the same IP, they can simply block the address and we won’t be able to scrape them for a while. Therefore, we need a way to “hide” the origin of the requests.
The solution
We will use proxies in order to do this. We will send our requests to the proxy instead of Amazon directly and the proxy will take care of passing our requests to the target website. That way, in the Amazon logs, it will appear that the request was coming from the proxy’s IP address and not our.
Of course, the idea behind it is to use multiple proxies in order to dilute all of our requests between each proxy. You can easily find lists of free proxies searching through Google. The issue with those is that they can be extremely slow. If speed matters for you, having a list of private or semi-private could be a better choice. Here is the implementation with Colly (and free proxies I found online):
| proxySwitcher, err := proxy.RoundRobinProxySwitcher("socks5://188.226.141.127:1080", "socks5://67.205.132.241:1080") | |
| if err != nil { | |
| log.Fatal(err) | |
| } | |
| c.SetProxyFunc(proxySwitcher) |
It’s possible that the proxies I used are not working anymore at the time you’re reading this article. Feel free to modify them.
We’re making usage of the proxy package from Colly. This package contains the method RoundRobinProxySwitcher . This method takes strings containing the protocol, the address and the port of the proxies as an argument. We then pass the proxySwitcher to the Collector with the help of the SetProxyFunc method. After this is done, Colly will send the requests through the proxies and select another proxy before each new request.
Write the result in a CSV file
Now that we have a proper way to fetch the data from Amazon, we just have to implement a way to store it. In this part, I’ll show you how to write the data in a CSV file. Of course, if you want to store the data in another way, feel free to do it. Colly has even some built-in storage implementation. Let’ start by modifying the beginning of our main function.
| func main() { | |
| fileName := "amazon_products.csv" | |
| file, err := os.Create(fileName) | |
| if err != nil { | |
| log.Fatalf("Could not create %s", fileName) | |
| } | |
| defer file.Close() | |
| writer := csv.NewWriter(file) | |
| defer writer.Flush() | |
| writer.Write([]string{"Product Name", "Stars", "Price"}) | |
| // ... | |
| } |
First, we create a file called amazon_products.csv . We then create a writer that will be used to save the data we fetch from Amazon in our file. On line 12, we write the first entry of the CSV file, defining the title of the column.
Then, in the callback function that we pass to the ForEach method, instead of writing the results we get, we’ll write them in the CSV file. Like this:
| writer.Write([]string{ | |
| productName, | |
| stars, | |
| price, | |
| }) |
Here are the results we get once we run the software now. You should have a new file in the working folder. If you open it with Excel (or a similar program), here is how it looks like:
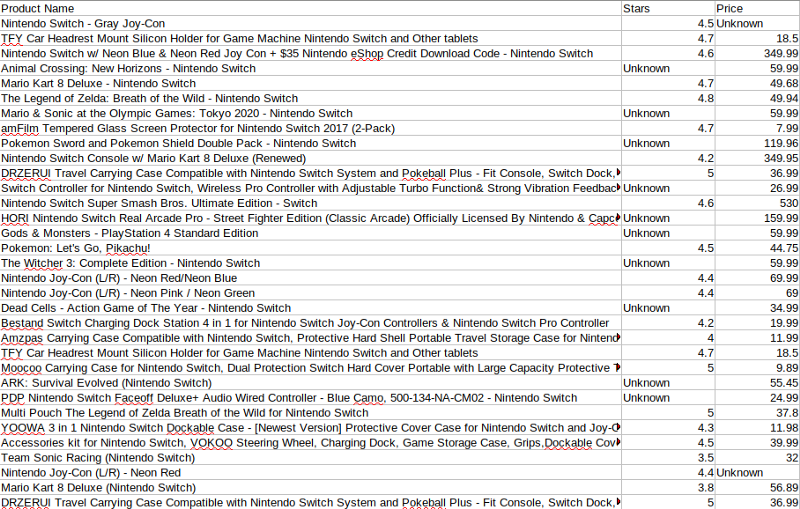
Conclusion
We implemented many options that improved the way our original scraper was working. There are still many things that can be done to improve it even further such as saving the data in a database, handle requests error (such as 404 when we request a page that doesn’t exist), etc. Don’t hesitate to improve this code or implement it on something else than Amazon, it’s a great exercise!
Disclaimer: Use the knowledge you’ve gained with this article wisely. Don’t send a huge number of requests to a website in a short amount of time. In the best case, they could just block you. In the worst, you could have problems with the law.
Thank you for reading my article. I hope it was useful for you. If you couldn’t follow along with the code, you can find the full project in this Github repository.
Happy scraping!