Let’s build a real-time scraper with Python, Flask, Requests, and Beautifulsoup!

Introduction
In this article, I will show you how to build a real-time scraper step-by-step. Once the project is done, you’ll be able to pass arguments to the scraper and use it just like you would use a normal API.
This article is similar to one in my previous article where I was talking about Scrapy and Scrapyrt. The difference here is that you can set up the endpoint to behave in a much more precise way.
As an example, we will see how to scrape data from Steam’s search results. I chose this example because the scraping part is quite straight forward and we’ll be able to focus more on the other aspects of the infrastructure.
Disclaimer: I won’t be spending too much time explaining in details the analysis and the scraping part. I’m assuming you already have some basics with Python, Requests, and Beautifulsoup, and that you know how to inspect a website to extract the CSS Selectors.
Analysis
Let’s first start investigating how the website is working. At the moment I’m writing those lines, the search bar is situated on the top right of the page.

Let’s type something in it and press Enter to observe the behavior of the website.
We are now redirected to the search results page. Here you can see a list of all the games related to your search. In my case, I have the following:
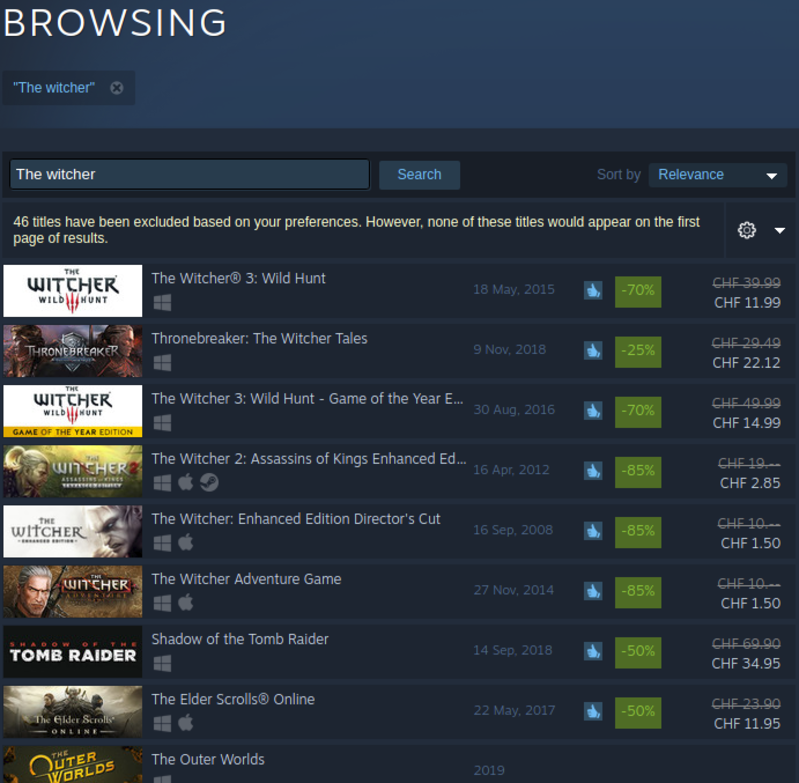
If we inspect the page, we notice that each result row is inside a <a> tag with a search_result_row class. The elements that we’re looking for are situated in the following selectors:
gameURL: situated in the href of 'a.search_result_row'
title: text of 'span.title'
releaseDate: text of 'div.search_released'
imgURL: src of 'div.search_capsule img'
price: text of 'div.search_price span strike'
discountedPrice: text of 'div.search_price'Another interesting element is the URL of the page.

We can see that the terms we are looking for are provided after the parameter term.
So far, after having those elements, we are capable of writing a simple script that fetches the data we need. Here is the example file main.py :
| import requests | |
| from bs4 import BeautifulSoup | |
| r = requests.get('https://store.steampowered.com/search/?term=The+witcher') | |
| soup = BeautifulSoup(r.text, 'html.parser') | |
| resultsRow = soup.find_all('a', {'class': 'search_result_row'}) | |
| results = [] | |
| for resultRow in resultsRow: | |
| gameURL = resultRow.get('href') | |
| title = resultRow.find('span', {'class': 'title'}).text | |
| releaseDate = resultRow.find('div', {'class': 'search_released'}).text | |
| imgURL = resultRow.select('div.search_capsule img')[0].get('src') | |
| price = None | |
| discountedPrice = None | |
| # The price is a bit more tricky to get since it is not always there | |
| # Basically we're checking if it is there, then we get rid of the | |
| # whitespaces. | |
| # Then we look for a discounted price, if it exists, we get the full | |
| # text of the div.search_price selector. This will return the full | |
| # price appended at the discounted price. | |
| # We then simply replace the price by an empty string to get only | |
| # the value of the discounted price. | |
| if (resultRow.select('div.search_price span strike')): | |
| price = resultRow.select('div.search_price span strike')[ | |
| 0].text.strip(' \t\n\r') | |
| if (resultRow.select('div.search_price')): | |
| rawDiscountPrice = resultRow.select( | |
| 'div.search_price')[0].text.strip(' \t\n\r') | |
| discountedPrice = rawDiscountPrice.replace(price, '') | |
| # Once formatted, the data are then appended to the results list | |
| results.append({ | |
| 'gameURL': gameURL, | |
| 'title': title, | |
| 'releaseDate': releaseDate, | |
| 'imgURL': imgURL, | |
| 'price': price, | |
| 'discountedPrice': discountedPrice | |
| }) | |
| print(results) |
You’ll need to install requests and beautifulsoup4 to be able to run this script. For this, I encourage you to use pipenv that allows you to install those in a virtual environment specially created for your project.
pipenv install requests beautifulsoup4
pipenv run python main.pyConversion to Real-Time Scraper
Before we begin, here is a little schema of the architecture we want to implement.
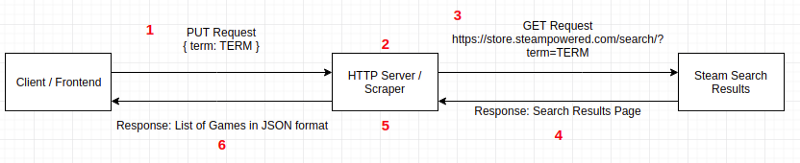
- At this stage, the client or frontend (depending on your needs) is making a PUT request containing the search term in the arguments to the HTTP server.
- The HTTP server receives the request and processes it to extract the search term.
- The server then makes a GET request to the steam store to pass it the search term.
- Steam sends back its search results page in an HTML format to the server
- At this point, the server receives the HTML, formats it to extract the game's data that we need.
- Once processed, the data are sent to the client/frontend in a nicely formatted JSON response.
An HTTP server with Flask and Flask_restful
Flask is a very useful Python framework made to quickly create a web server. Flask_restful is an extension for Flask that allows us to develop easily a REST API.
First, let’s install those two libraries by running the following command:
pipenv install Flask flask-restful
Let’s import those two libraries inmain.py
| from flask import Flask | |
| from flask_restful import Resource, Api, reqparse |
You can now create the Flask application and declare it at the beginning of the file after the imports.
| app = Flask(__name__) | |
| api = Api(app) |
Let’s refactor the scraper that we had previously to tell Flask that it should now be part of a resource and accessible via a PUT request. For that, we need to create a new class called SteamSearch (the name is up to you) that inherits from the Resource that we import from flask_restful . We then put our code in a method named put to indicated that it can be accessed by this type of request. The final result looks like the following:
| class SteamSearch(Resource): | |
| def put(self): | |
| r = requests.get('https://store.steampowered.com/search/?term=The+witcher') | |
| soup = BeautifulSoup(r.text, 'html.parser') | |
| resultsRow = soup.find_all('a', {'class': 'search_result_row'}) | |
| results = [] | |
| for resultRow in resultsRow: | |
| gameURL = resultRow.get('href') | |
| title = resultRow.find('span', {'class': 'title'}).text | |
| releaseDate = resultRow.find('div', {'class': 'search_released'}).text | |
| imgURL = resultRow.select('div.search_capsule img')[0].get('src') | |
| price = None | |
| discountedPrice = None | |
| if (resultRow.select('div.search_price span strike')): | |
| price = resultRow.select('div.search_price span strike')[ | |
| 0].text.strip(' \t\n\r') | |
| if (resultRow.select('div.search_price')): | |
| rawDiscountPrice = resultRow.select( | |
| 'div.search_price')[0].text.strip(' \t\n\r') | |
| discountedPrice = rawDiscountPrice.replace(price, '') | |
| # Once formatted, the data are then appended to the results list | |
| results.append({ | |
| 'gameURL': gameURL, | |
| 'title': title, | |
| 'releaseDate': releaseDate, | |
| 'imgURL': imgURL, | |
| 'price': price, | |
| 'discountedPrice': discountedPrice | |
| }) | |
| return results |
At the bottom of the file, we need to say to Flask that the StreamSearch class is a part of the API. We also need to specify a route where the resource can be requested. For this, you can use the following code:
| api.add_resource(SteamSearch, '/steam_search') | |
| if __name__ == '__main__': | |
| app.run(debug=True) |
The lines 3 and 4 are simply there to run the app. The parameter debug=True is there to make our life easier during the development by auto-refreshing the server when we make modification in the code. The value needs to be set to wrong if you want to deploy the server in production!
The last thing we need to do is to handle the argument passed in the PUT request our server receives. This can be achieved with the help of reqparse that we imported from flask_restful .
With this helper, we can define what arguments can be sent in the request body, what are their types, are they required, etc. You can add the following code at the very top of the put method.
| parser = reqparse.RequestParser() | |
| parser.add_argument('term', required=True, help='A search term needs to be provided') | |
| args = parser.parse_args() |
After this step, the search time can be accessed in the put method via args.term . If you need other arguments, you can add as many as you want following the second line of the example code.
There is one last step that needs to be done before we finish our little project: it is possible that the search term that we send to the server contains special characters or whitespaces. This might make the GET request to Steam failed. To solve this problem, we need to encode the term we receive with the help of the parser included in the urllib library.
| from urllib import parse |
Right before we make the request to the Steam store, we can add those lines to our code.
| formattedSearchTerm = parse.urlencode({'term': args.term}) | |
| r = requests.get(f'https://store.steampowered.com/search/?{formattedSearchTerm}') |
The first line, as I said previously, will format the term if it contains non-supported characters. The output of this function will be something liketerm=$valueOfArgsTerm .
We then pass this value to the GET request and we are done!
In the end, the code should look like this:
| import requests | |
| from bs4 import BeautifulSoup | |
| from urllib import parse | |
| from flask import Flask | |
| from flask_restful import Resource, Api, reqparse | |
| app = Flask(__name__) | |
| api = Api(app) | |
| class SteamSearch(Resource): | |
| def put(self): | |
| parser = reqparse.RequestParser() | |
| parser.add_argument('term', required=True, | |
| help='A search term needs to be provided') | |
| args = parser.parse_args() | |
| formattedSearchTerm = parse.urlencode({'term': args.term}) | |
| r = requests.get( | |
| f'https://store.steampowered.com/search/?{formattedSearchTerm}') | |
| soup = BeautifulSoup(r.text, 'html.parser') | |
| resultsRow = soup.find_all('a', {'class': 'search_result_row'}) | |
| results = [] | |
| for resultRow in resultsRow: | |
| gameURL = resultRow.get('href') | |
| title = resultRow.find('span', {'class': 'title'}).text | |
| releaseDate = resultRow.find( | |
| 'div', {'class': 'search_released'}).text | |
| imgURL = resultRow.select('div.search_capsule img')[0].get('src') | |
| price = None | |
| discountedPrice = None | |
| if (resultRow.select('div.search_price span strike')): | |
| price = resultRow.select('div.search_price span strike')[ | |
| 0].text.strip(' \t\n\r') | |
| if (resultRow.select('div.search_price')): | |
| rawDiscountPrice = resultRow.select( | |
| 'div.search_price')[0].text.strip(' \t\n\r') | |
| discountedPrice = rawDiscountPrice.replace(price, '') | |
| results.append({ | |
| 'gameURL': gameURL, | |
| 'title': title, | |
| 'releaseDate': releaseDate, | |
| 'imgURL': imgURL, | |
| 'price': price, | |
| 'discountedPrice': discountedPrice | |
| }) | |
| return results | |
| api.add_resource(SteamSearch, '/steam_search') | |
| if __name__ == '__main__': | |
| app.run(debug=True) |
You can start your HTTP server with pipenv run python main.py
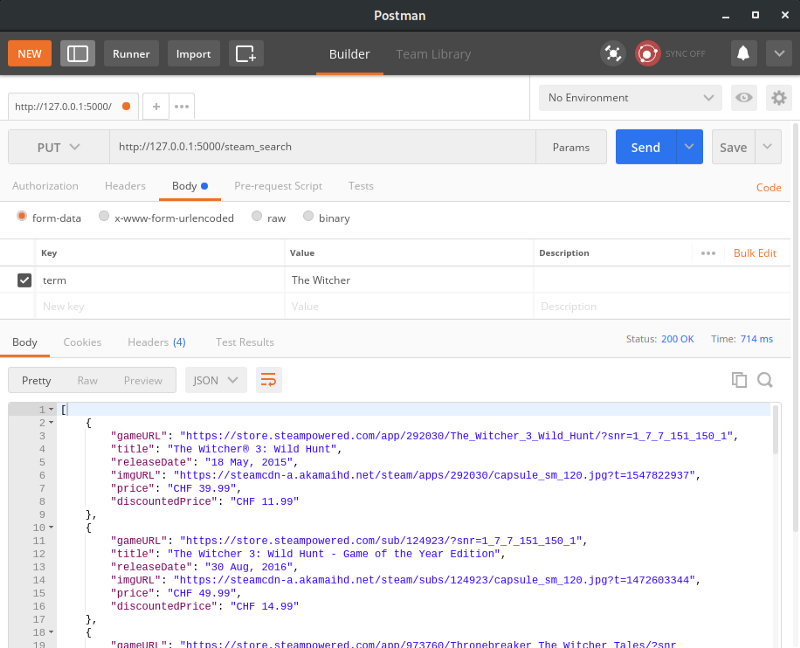
Let’s try to make a request to our server with Postman. The result will look like this:
Conclusion
Thank you for reading this article! If you want to train a bit more on this topic, you can try to make your server able to handle the page number of the steam search results.

I’ll be soon posting a follow-up article where we will see how we can deploy this live scraper project to the cloud so we can use it in a “real-world” situation. See you soon!